JobManager高可用性(HA)
JobManager协调每个Flink部署。它负责_调度_和_资源管理_。
默认情况下,每个Flink群集都有一个JobManager实例。这会产生_单点故障_(SPOF):如果JobManager崩溃,则无法提交新程序并且运行程序失败。
使用JobManager High Availability,您可以从JobManager故障中恢复,从而消除_SPOF_。您可以为独立和YARN群集配置高可用性。
独立群集高可用性
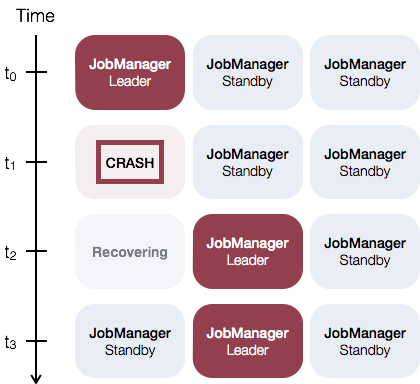
独立集群的JobManager高可用性的一般概念是,任何时候都有一个Master JobManager和多个Slave JobManagers,以便在Leader失败时接管领导。这保证了没有单点故障,一旦Slave JobManager取得领导,程序就可以取得进展。Slave 和主JobManager实例之间没有明确的区别。每个JobManager都可以充当主服务器或Slave 服务器。
例如,请考虑以下三个JobManager实例的设置:
配置
要启用JobManager高可用性,您必须将高可用性模式设置为_zookeeper_,配置ZooKeeper quorum并设置包含所有JobManagers主机及其Web UI端口的主服务器文件。
Flink利用ZooKeeper在所有正在运行的JobManager实例之间进行_分布式协调_。ZooKeeper是Flink的独立服务,通过Leader选举和轻量级一致状态存储提供高度可靠的分布式协调。有关ZooKeeper的更多信息,请查看ZooKeeper的入门指南。Flink包含用于引导简单ZooKeeper安装的脚本。
Masters 文件(Masters )
要启动HA群集,请在以下位置配置_主_文件conf/masters:
-
masters文件:_masters文件_包含启动JobManagers的所有主机以及Web用户界面绑定的端口。
``` jobManagerAddress1:webUIPort1 [...] jobManagerAddressX:webUIPortX
```
默认情况下,JobManager将为进程间通信选择一个_随机端口_。您可以通过high-availability.jobmanager.portKeys更改此设置。此Keys接受单个端口(例如50010),范围(50000-50025)或两者的组合(50010,50011,50020-50025,50050-50075)。
配置文件(flink-conf.yaml)
要启动HA群集,请将以下配置键添加到conf/flink-conf.yaml:
-
高可用性模式(必需):高可用性模式_必须被在设置
conf/flink-conf.yaml于_zookeeper,以使高可用性模式。high-availability: zookeeper -
ZooKeeper quorum(必需):_ZooKeeper quorum_是ZooKeeper服务器的复制组,它提供分布式协调服务。
high-availability.zookeeper.quorum:address1:2181 [,...],addressX:2181每个_addressX:port_指的是一个ZooKeeper服务器,Flink可以在给定的地址和端口访问它。
-
ZooKeeper root(推荐):根ZooKeeper节点,在该_节点_下放置所有集群节点。
``` high-availability.zookeeper.path.root:/ flink
```
-
ZooKeeper cluster-id(推荐):cluster-id ZooKeeper节点,在该_节点_下放置集群的所有必需协调数据。
high-availability.cluster-id:/ default_ns#important:每个群集自定义要点:在运行YARN群集,按作业YARN会话或其他群集管理器时,不应手动设置此值。在这些情况下,将根据应用程序ID自动生成cluster-id。手动设置cluster-id会覆盖YARN中的此行为。反过来,使用-z CLI选项指定cluster-id会覆盖手动配置。如果在裸机上运行多个Flink HA群集,则必须为每个群集手动配置单独的群集ID。
-
存储目录(必需):JobManager元数据保存在文件系统_storageDir中_,只有指向此状态的指针存储在ZooKeeper中。
``` high-availability.storageDir:hdfs:/// flink / recovery
```
该
storageDir存储所有元数据需要恢复JobManager失败。
配置主服务器和ZooKeeper quorum后,您可以像往常一样使用提供的集群启动脚本。他们将启动HA群集。请记住,调用脚本时必须运行ZooKeeper quorum,并确保为要启动的每个HA群集配置单独的ZooKeeper根路径。
示例:具有2个JobManagers的独立群集
-
配置高可用性模式和 zookeeper.quorum 在
conf/flink-conf.yaml:high-availability: zookeeper high-availability.zookeeper.quorum:localhost:2181 high-availability.zookeeper.path.root:/ flink high-availability.cluster-id:/ cluster_one#important:custom per cluster high-availability.storageDir: HDFS:///Flink/恢复 -
配置Masters 在
conf/masters:localhost:8081 localhost:8082 -
配置ZooKeeper的服务器中
conf/zoo.cfg(目前它只是可以运行每台机器的单一的ZooKeeper服务器):server.0 =localhost:2888:3888 -
启动ZooKeeper quorum:
$ bin / start-zookeeper-quorum.sh 在主机localhost上启动zookeeper守护程序。 -
启动HA群集:
$ bin / start-cluster.sh 在ZooKeeper quorum中启动具有2个主服务器和1个对等服务器的HA集群。 在主机localhost上启动jobmanager守护程序。 在主机localhost上启动jobmanager守护程序。 在主机localhost上启动taskmanager守护程序。 -
停止ZooKeeper quorum和集群:
$ bin / stop-cluster.sh 在localhost上停止taskmanager守护进程(pid:7647)。 在主机localhost上停止jobmanager守护进程(pid:7495)。 在主机localhost上停止jobmanager守护进程(pid:7349)。 $ bin / stop-zookeeper-quorum.sh 在主机localhost上停止zookeeper守护进程(pid:7101)。
YARN群集高可用性
在运行高可用性YARN群集时,我们不会运行多个JobManager(ApplicationMaster)实例,而只会运行一个,由YARN在失败时重新启动。确切的行为取决于您使用的特定YARN版本。
配置
最大应用程序主要尝试次数(yarn-site.xml)
您必须配置为尝试应用Masters 的最大数量的 YARN的设置yarn-site.xml:
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
<description>
The maximum number of application master execution attempts.
</description>
</property>
当前YARN版本的默认值为2(表示允许单个JobManager失败)。
申请尝试(flink-conf.yaml)
除HA配置(参见上文)外,您还必须配置最大尝试次数conf/flink-conf.yaml:
yarn.application-attempts:10
这意味着在YARN未通过应用程序(9次重试+ 1次初始尝试)之前,应用程序可以重新启动9次以进行失败尝试。如果YARN 算子操作需要,YARN可以执行其他重新启动:抢占,节点硬件故障或重新启动或NodeManager重新同步。这些重启不计入yarn.application-attempts,请参阅Jian Fang的博客文章。重要的是要注意yarn.resourcemanager.am.max-attempts应用程序重新启动的上限。因此,Flink中设置的应用程序尝试次数不能超过启动YARN的YARN群集设置。
容器关闭行为
- YARN 2.3.0 <版本<2.4.0。如果应用程序主机失败,则重新启动所有容器。
- YARN 2.4.0 <版本<2.6.0。TaskManager容器在应用程序主故障期间保持活动状态。这具有以下优点:启动时间更快并且用户不必再等待再次获得容器资源。
- YARN 2.6.0 <= version:将尝试失败有效性间隔设置为Flinks的Akka超时值。尝试失败有效性间隔表示只有在系统在一个间隔期间看到最大应用程序尝试次数后才会终止应用程序。这避免了持久的工作会耗尽它的应用程序尝试。
注意:Hadoop YARN 2.4.0有一个主要错误(在2.5.0中修复),阻止重新启动的Application Master / Job Manager容器重启容器。有关详细信息,请参阅FLINK-4142。我们建议至少在YARN上使用Hadoop 2.5.0进行高可用性设置。
示例:高度可用的YARN会话
-
配置HA模式和 zookeeper.quorum 在
conf/flink-conf.yaml:high-availability: zookeeper high-availability.zookeeper.quorum:localhost:2181 high-availability.storageDir:hdfs:/// flink / recovery high-availability.zookeeper.path.root:/ flink yarn.application-attempts:10 -
配置ZooKeeper的服务器中
conf/zoo.cfg(目前它只是可以运行每台机器的单一的ZooKeeper服务器):server.0 =localhost:2888:3888 -
启动ZooKeeper quorum:
$ bin / start-zookeeper-quorum.sh 在主机localhost上启动zookeeper守护程序。 -
启动HA群集:
$ bin / yarn-session.sh -n 2
配置Zookeeper安全性
如果ZooKeeper使用Kerberos以安全模式运行,则可以flink-conf.yaml根据需要覆盖以下配置:
zookeeper.sasl.service-name:zookeeper #default是“zookeeper”。如果ZooKeeper quorum配置为
#具有不同的服务名称,则可以在此处提供。
zookeeper.sasl.login-context-name:Client#default是“Client”。该值需要匹配
“security.kerberos.login.contexts”中配置的值#之一。
有关Kerberos安全性的Flink配置的更多信息,请参阅此处。您还可以在此处找到有关Flink内部如何设置基于Kerberos的安全性的更多详细信息。
Bootstrap ZooKeeper
如果您没有正在运行的ZooKeeper安装,则可以使用Flink附带的帮助程序脚本。
中有一个ZooKeeper配置模板conf/zoo.cfg。您可以将主机配置为使用server.X条目运行ZooKeeper ,其中X是每个服务器的唯一ID:
server.X = addressX:peerPort:leaderPort
[...]
server.Y = addressY:peerPort:leaderPort
该脚本bin/start-zookeeper-quorum.sh将在每个配置的主机上启动ZooKeeper服务器。启动的进程通过Flink打包器启动ZooKeeper服务器,该打包器从中读取配置conf/zoo.cfg并确保为方便起见设置一些必需的配置值。在生产设置中,建议您管理自己的ZooKeeper安装。
