图API
图表表示
在Gelly中,a Graph由DataSet顶点和DataSet边缘表示。
所述Graph节点通过所表示的Vertex类型。A Vertex由唯一ID和值定义。VertexID应该实现Comparable接口。可以通过将值类型设置为来表示没有值的顶点NullValue。
// create a new vertex with a Long ID and a String value
Vertex<Long, String> v = new Vertex<Long, String>(1L, "foo");
// create a new vertex with a Long ID and no value
Vertex<Long, NullValue> v = new Vertex<Long, NullValue>(1L, NullValue.getInstance());
// create a new vertex with a Long ID and a String value val v = new Vertex(1L, "foo")
// create a new vertex with a Long ID and no value val v = new Vertex(1L, NullValue.getInstance())
图形边缘由Edge类型表示。An Edge由源ID(源的ID Vertex),目标ID(目标的ID Vertex)和可选值定义。源ID和目标ID应与ID的类型相同Vertex。没有值的边具有NullValue值类型。
Edge<Long, Double> e = new Edge<Long, Double>(1L, 2L, 0.5);
// reverse the source and target of this edge
Edge<Long, Double> reversed = e.reverse();
Double weight = e.getValue(); // weight = 0.5
val e = new Edge(1L, 2L, 0.5)
// reverse the source and target of this edge val reversed = e.reverse
val weight = e.getValue // weight = 0.5
在Gelly中,Edge始终从源顶点指向目标顶点。Graph如果A Edge包含Edge从目标顶点到源顶点的匹配,则A 可以是无向的。
图形创建
您可以Graph通过以下方式创建:
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<Vertex<String, Long>> vertices = ...
DataSet<Edge<String, Double>> edges = ...
Graph<String, Long, Double> graph = Graph.fromDataSet(vertices, edges, env);
val env = ExecutionEnvironment.getExecutionEnvironment
val vertices: DataSet[Vertex[String, Long]] = ...
val edges: DataSet[Edge[String, Double]] = ...
val graph = Graph.fromDataSet(vertices, edges, env)
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<Tuple2<String, String>> edges = ...
Graph<String, NullValue, NullValue> graph = Graph.fromTuple2DataSet(edges, env);
val env = ExecutionEnvironment.getExecutionEnvironment
val edges: DataSet[(String, String)] = ...
val graph = Graph.fromTuple2DataSet(edges, env)
-
从
DataSet的Tuple3和可选DataSet的Tuple2。在这种情况下,Gelly会将每个转换Tuple3为aEdge,其中第一个字段将是源ID,第二个字段将是目标ID,第三个字段将是边缘值。等价地,每个Tuple2都将转换为aVertex,其中第一个字段将是顶点ID,第二个字段将是顶点值: - Scala
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<Tuple2<String, Long>> vertexTuples = env.readCsvFile("path/to/vertex/input").types(String.class, Long.class);
DataSet<Tuple3<String, String, Double>> edgeTuples = env.readCsvFile("path/to/edge/input").types(String.class, String.class, Double.class);
Graph<String, Long, Double> graph = Graph.fromTupleDataSet(vertexTuples, edgeTuples, env);
-
来自Edge数据的CSV文件和Vertex数据的可选CSV文件。在这种情况下,Gelly会将Edge CSV文件中的每一行转换为a
Edge,其中第一个字段将是源ID,第二个字段将是目标ID,第三个字段(如果存在)将是边缘值。等效地,可选的顶点CSV文件中的每一行将被转换为aVertex,其中第一个字段将是顶点ID,第二个字段(如果存在)将是顶点值。为了Graph从一个GraphCsvReader人必须指定类型,使用以下方法之一: -
types(Class<K> vertexKey, Class<VV> vertexValue,Class<EV> edgeValue):存在顶点和边值。 edgeTypes(Class<K> vertexKey, Class<EV> edgeValue):图表具有边缘值,但没有顶点值。vertexTypes(Class<K> vertexKey, Class<VV> vertexValue):图表具有顶点值,但没有边缘值。keyType(Class<K> vertexKey):图表没有顶点值,没有边缘值。
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// create a Graph with String Vertex IDs, Long Vertex values and Double Edge values
Graph<String, Long, Double> graph = Graph.fromCsvReader("path/to/vertex/input", "path/to/edge/input", env)
.types(String.class, Long.class, Double.class);
// create a Graph with neither Vertex nor Edge values
Graph<Long, NullValue, NullValue> simpleGraph = Graph.fromCsvReader("path/to/edge/input", env).keyType(Long.class);
val env = ExecutionEnvironment.getExecutionEnvironment
val vertexTuples = env.readCsvFile[String, Long]("path/to/vertex/input")
val edgeTuples = env.readCsvFile[String, String, Double]("path/to/edge/input")
val graph = Graph.fromTupleDataSet(vertexTuples, edgeTuples, env)
- from a CSV file of Edge data and an optional CSV file of Vertex data. In this case, Gelly will convert each row from the Edge CSV file to an
Edge. The first field of the each row will be the source ID, the second field will be the target ID and the third field (if present) will be the edge value. If the edges have no associated value, set the edge value type parameter (3rd type argument) toNullValue. You can also specify that the vertices are initialized with a vertex value. If you provide a path to a CSV file viapathVertices, each row of this file will be converted to aVertex. The first field of each row will be the vertex ID and the second field will be the vertex value. If you provide a vertex value initializerMapFunctionvia thevertexValueInitializerparameter, then this function is used to generate the vertex values. The set of vertices will be created automatically from the edges input. If the vertices have no associated value, set the vertex value type parameter (2nd type argument) toNullValue. The vertices will then be automatically created from the edges input with vertex value of typeNullValue.
val env = ExecutionEnvironment.getExecutionEnvironment
// create a Graph with String Vertex IDs, Long Vertex values and Double Edge values val graph = Graph.fromCsvReader[String, Long, Double](
pathVertices = "path/to/vertex/input",
pathEdges = "path/to/edge/input",
env = env)
// create a Graph with neither Vertex nor Edge values val simpleGraph = Graph.fromCsvReader[Long, NullValue, NullValue](
pathEdges = "path/to/edge/input",
env = env)
// create a Graph with Double Vertex values generated by a vertex value initializer and no Edge values val simpleGraph = Graph.fromCsvReader[Long, Double, NullValue](
pathEdges = "path/to/edge/input",
vertexValueInitializer = new MapFunction[Long, Double]() {
def map(id: Long): Double = {
id.toDouble
}
},
env = env)
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
List<Vertex<Long, Long>> vertexList = new ArrayList...
List<Edge<Long, String>> edgeList = new ArrayList...
Graph<Long, Long, String> graph = Graph.fromCollection(vertexList, edgeList, env);
如果在创建图形期间没有提供顶点输入,Gelly将自动Vertex DataSet从边缘输入生成。在这种情况下,创建的顶点将没有值。或者,您可以提供一个MapFunction作为创建方法的参数,以初始化Vertex值:
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// initialize the vertex value to be equal to the vertex ID
Graph<Long, Long, String> graph = Graph.fromCollection(edgeList,
new MapFunction<Long, Long>() {
public Long map(Long value) {
return value;
}
}, env);
val env = ExecutionEnvironment.getExecutionEnvironment
val vertexList = List(...)
val edgeList = List(...)
val graph = Graph.fromCollection(vertexList, edgeList, env)
If no vertex input is provided during Graph creation, Gelly will automatically produce the Vertex DataSet from the edge input. In this case, the created vertices will have no values. Alternatively, you can provide a MapFunction as an argument to the creation method, in order to initialize the Vertex values:
val env = ExecutionEnvironment.getExecutionEnvironment
// initialize the vertex value to be equal to the vertex ID
val graph = Graph.fromCollection(edgeList,
new MapFunction[Long, Long] {
def map(id: Long): Long = id
}, env)
图表属性
Gelly包含以下用于检索各种Graph属性和指标的方法:
// get the Vertex DataSet
DataSet<Vertex<K, VV>> getVertices()
// get the Edge DataSet
DataSet<Edge<K, EV>> getEdges()
// get the IDs of the vertices as a DataSet
DataSet<K> getVertexIds()
// get the source-target pairs of the edge IDs as a DataSet
DataSet<Tuple2<K, K>> getEdgeIds()
// get a DataSet of <vertex ID, in-degree> pairs for all vertices
DataSet<Tuple2<K, LongValue>> inDegrees()
// get a DataSet of <vertex ID, out-degree> pairs for all vertices
DataSet<Tuple2<K, LongValue>> outDegrees()
// get a DataSet of <vertex ID, degree> pairs for all vertices, where degree is the sum of in- and out- degrees
DataSet<Tuple2<K, LongValue>> getDegrees()
// get the number of vertices
long numberOfVertices()
// get the number of edges
long numberOfEdges()
// get a DataSet of Triplets<srcVertex, trgVertex, edge>
DataSet<Triplet<K, VV, EV>> getTriplets()
// get the Vertex DataSet getVertices: DataSet[Vertex[K, VV]]
// get the Edge DataSet getEdges: DataSet[Edge[K, EV]]
// get the IDs of the vertices as a DataSet getVertexIds: DataSet[K]
// get the source-target pairs of the edge IDs as a DataSet getEdgeIds: DataSet[(K, K)]
// get a DataSet of <vertex ID, in-degree> pairs for all vertices inDegrees: DataSet[(K, LongValue)]
// get a DataSet of <vertex ID, out-degree> pairs for all vertices outDegrees: DataSet[(K, LongValue)]
// get a DataSet of <vertex ID, degree> pairs for all vertices, where degree is the sum of in- and out- degrees getDegrees: DataSet[(K, LongValue)]
// get the number of vertices numberOfVertices: Long
// get the number of edges numberOfEdges: Long
// get a DataSet of Triplets<srcVertex, trgVertex, edge> getTriplets: DataSet[Triplet[K, VV, EV]]
图形转换
-
Map:Gelly提供了在顶点值或边缘值上应用贴图变换的专门方法。
mapVertices并mapEdges返回一个新的Graph,其中顶点(或边)的ID保持不变,而值根据提供的用户定义的映射函数进行转换。Map函数还允许更改顶点或边值的类型。 - Scala
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
Graph<Long, Long, Long> graph = Graph.fromDataSet(vertices, edges, env);
// increment each vertex value by one
Graph<Long, Long, Long> updatedGraph = graph.mapVertices(
new MapFunction<Vertex<Long, Long>, Long>() {
public Long map(Vertex<Long, Long> value) {
return value.getValue() + 1;
}
});
val env = ExecutionEnvironment.getExecutionEnvironment
val graph = Graph.fromDataSet(vertices, edges, env)
// increment each vertex value by one val updatedGraph = graph.mapVertices(v => v.getValue + 1)
-
翻译:Gelly提供了用于翻译顶点和边ID(
translateGraphIDs),顶点值(translateVertexValues)或边值(translateEdgeValues)的值和/或类型的专用方法。翻译由用户定义的Map函数执行,其中几个在org.apache.flink.graph.asm.translate包中提供。MapFunction所有三种翻译方法都可以使用相同的方法。 - Scala
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
Graph<Long, Long, Long> graph = Graph.fromDataSet(vertices, edges, env);
// translate each vertex and edge ID to a String
Graph<String, Long, Long> updatedGraph = graph.translateGraphIds(
new MapFunction<Long, String>() {
public String map(Long id) {
return id.toString();
}
});
// translate vertex IDs, edge IDs, vertex values, and edge values to LongValue
Graph<LongValue, LongValue, LongValue> updatedGraph = graph
.translateGraphIds(new LongToLongValue())
.translateVertexValues(new LongToLongValue())
.translateEdgeValues(new LongToLongValue())
val env = ExecutionEnvironment.getExecutionEnvironment
val graph = Graph.fromDataSet(vertices, edges, env)
// translate each vertex and edge ID to a String val updatedGraph = graph.translateGraphIds(id => id.toString)
-
过滤器:过滤器变换将应用用户定义的过滤器函数应用于顶点或边缘
Graph。filterOnEdges将创建原始图的子图,仅保存满足所提供谓词的边。请注意,不会修改顶点数据集。分别filterOnVertices对图的顶点应用滤镜。从生成的边数据集中删除其源和/或目标不满足顶点谓词的边。该subgraph方法可用于同时将滤波函数应用于顶点和边。 - Scala
Graph<Long, Long, Long> graph = ...
graph.subgraph(
new FilterFunction<Vertex<Long, Long>>() {
public boolean filter(Vertex<Long, Long> vertex) {
// keep only vertices with positive values
return (vertex.getValue() > 0);
}
},
new FilterFunction<Edge<Long, Long>>() {
public boolean filter(Edge<Long, Long> edge) {
// keep only edges with negative values
return (edge.getValue() < 0);
}
})
val graph: Graph[Long, Long, Long] = ...
// keep only vertices with positive values
// and only edges with negative values graph.subgraph((vertex => vertex.getValue > 0), (edge => edge.getValue < 0))
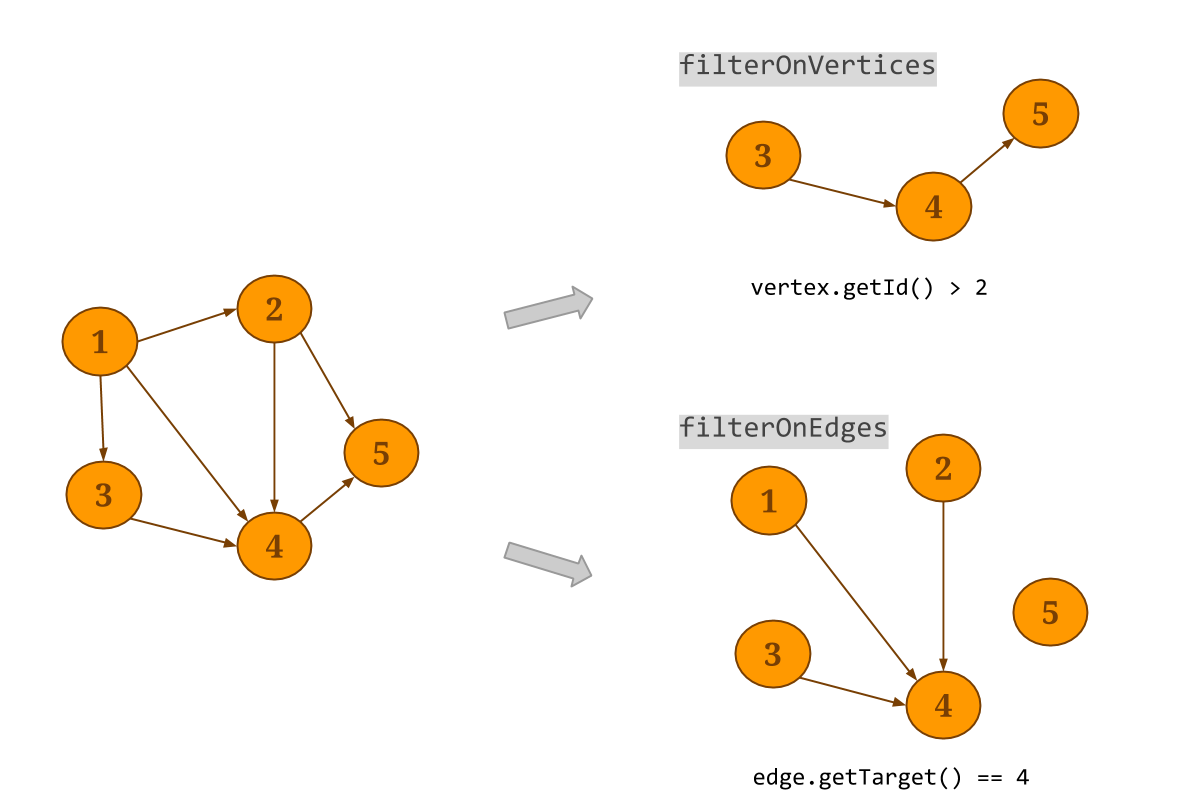
-
Join:Gelly提供了将顶点和边缘数据集与其他输入数据集连接的专用方法。
joinWithVertices使用Tuple2输入数据集连接顶点。使用顶点ID和Tuple2输入的第一个字段作为连接键来执行连接。该方法返回一个新的Graph,其中顶点值已根据提供的用户定义的转换函数进行更新。类似地,输入数据集可以使用三种方法之一与边连接。joinWithEdges期望的输入DataSet的Tuple3,并关联对源和目标顶点ID的组合键。joinWithEdgesOnSource期望一个DataSet的Tuple2并关联上边缘和输入数据集的所述第一属性的源Keys和joinWithEdgesOnTarget期望一个DataSet的Tuple2并连接边的目标键和输入数据集的第一个属性。所有这三种方法都在边缘和输入数据集值上应用变换函数。请注意,如果输入数据集多次包含键,则所有Gelly连接方法将仅考虑遇到的第一个值。 - Scala
Graph<Long, Double, Double> network = ...
DataSet<Tuple2<Long, LongValue>> vertexOutDegrees = network.outDegrees();
// assign the transition probabilities as the edge weights
Graph<Long, Double, Double> networkWithWeights = network.joinWithEdgesOnSource(vertexOutDegrees,
new VertexJoinFunction<Double, LongValue>() {
public Double vertexJoin(Double vertexValue, LongValue inputValue) {
return vertexValue / inputValue.getValue();
}
});
val network: Graph[Long, Double, Double] = ...
val vertexOutDegrees: DataSet[(Long, LongValue)] = network.outDegrees
// assign the transition probabilities as the edge weights val networkWithWeights = network.joinWithEdgesOnSource(vertexOutDegrees, (v1: Double, v2: LongValue) => v1 / v2.getValue)
-
反转:该
reverse()方法返回一个新的Graph,其中所有边的方向都已反转。 -
无根据:在Gelly中,a
Graph总是被指挥。可以通过向图形添加所有相反方向边来表示无向图。为此,Gelly提供了这种getUndirected()方法。 -
Union:Gelly的
union()方法对指定图形的顶点和边集以及当前图执行并集 算子操作。从结果中删除重复的顶点Graph,而如果存在重复的边,则将保存这些顶点。
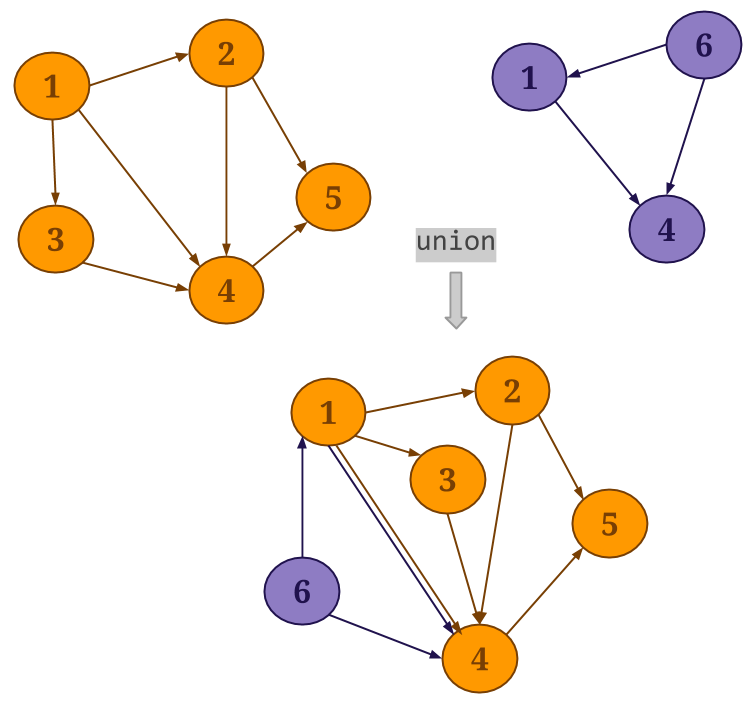
-
差异:Gelly的
difference()方法对当前图形和指定图形的顶点和边集进行差异。 -
Intersect:Gelly的
intersect()方法在当前图形和指定图形的边集上执行相交。结果是一个新的Graph,包含两个输入图中存在的所有边。如果两条边具有相同的源标识符,目标标识符和边缘值,则认为它们是相等的。结果图中的顶点没有值。如果需要顶点值,则可以使用该joinWithVertices()方法从一个输入图中检索它们。根据参数distinct,相等的边在结果中包含一次,Graph或者在输入图中有相同的边对。 - Scala
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// create first graph from edges {(1, 3, 12) (1, 3, 13), (1, 3, 13)}
List<Edge<Long, Long>> edges1 = ...
Graph<Long, NullValue, Long> graph1 = Graph.fromCollection(edges1, env);
// create second graph from edges {(1, 3, 13)}
List<Edge<Long, Long>> edges2 = ...
Graph<Long, NullValue, Long> graph2 = Graph.fromCollection(edges2, env);
// Using distinct = true results in {(1,3,13)}
Graph<Long, NullValue, Long> intersect1 = graph1.intersect(graph2, true);
// Using distinct = false results in {(1,3,13),(1,3,13)} as there is one edge pair
Graph<Long, NullValue, Long> intersect2 = graph1.intersect(graph2, false);
val env = ExecutionEnvironment.getExecutionEnvironment
// create first graph from edges {(1, 3, 12) (1, 3, 13), (1, 3, 13)} val edges1: List[Edge[Long, Long]] = ...
val graph1 = Graph.fromCollection(edges1, env)
// create second graph from edges {(1, 3, 13)} val edges2: List[Edge[Long, Long]] = ...
val graph2 = Graph.fromCollection(edges2, env)
// Using distinct = true results in {(1,3,13)} val intersect1 = graph1.intersect(graph2, true)
// Using distinct = false results in {(1,3,13),(1,3,13)} as there is one edge pair val intersect2 = graph1.intersect(graph2, false)
-
图形突变
Gelly包含以下用于在输入中添加和删除顶点和边的方法Graph:
// adds a Vertex to the Graph. If the Vertex already exists, it will not be added again.
Graph<K, VV, EV> addVertex(final Vertex<K, VV> vertex)
// adds a list of vertices to the Graph. If the vertices already exist in the graph, they will not be added once more.
Graph<K, VV, EV> addVertices(List<Vertex<K, VV>> verticesToAdd)
// adds an Edge to the Graph. If the source and target vertices do not exist in the graph, they will also be added.
Graph<K, VV, EV> addEdge(Vertex<K, VV> source, Vertex<K, VV> target, EV edgeValue)
// adds a list of edges to the Graph. When adding an edge for a non-existing set of vertices, the edge is considered invalid and ignored.
Graph<K, VV, EV> addEdges(List<Edge<K, EV>> newEdges)
// removes the given Vertex and its edges from the Graph.
Graph<K, VV, EV> removeVertex(Vertex<K, VV> vertex)
// removes the given list of vertices and their edges from the Graph
Graph<K, VV, EV> removeVertices(List<Vertex<K, VV>> verticesToBeRemoved)
// removes *all* edges that match the given Edge from the Graph.
Graph<K, VV, EV> removeEdge(Edge<K, EV> edge)
// removes *all* edges that match the edges in the given list
Graph<K, VV, EV> removeEdges(List<Edge<K, EV>> edgesToBeRemoved)
// adds a Vertex to the Graph. If the Vertex already exists, it will not be added again. addVertex(vertex: Vertex[K, VV])
// adds a list of vertices to the Graph. If the vertices already exist in the graph, they will not be added once more. addVertices(verticesToAdd: List[Vertex[K, VV]])
// adds an Edge to the Graph. If the source and target vertices do not exist in the graph, they will also be added. addEdge(source: Vertex[K, VV], target: Vertex[K, VV], edgeValue: EV)
// adds a list of edges to the Graph. When adding an edge for a non-existing set of vertices, the edge is considered invalid and ignored. addEdges(edges: List[Edge[K, EV]])
// removes the given Vertex and its edges from the Graph. removeVertex(vertex: Vertex[K, VV])
// removes the given list of vertices and their edges from the Graph removeVertices(verticesToBeRemoved: List[Vertex[K, VV]])
// removes *all* edges that match the given Edge from the Graph. removeEdge(edge: Edge[K, EV])
// removes *all* edges that match the edges in the given list removeEdges(edgesToBeRemoved: List[Edge[K, EV]])
邻里方法
邻域方法允许顶点在其第一跳邻域上执行聚合。 reduceOnEdges()可以用于计算顶点的相邻边缘的值的聚合,并且reduceOnNeighbors()可以用于计算相邻顶点的值的聚合。这些方法假设关联和交换聚合并在内部利用组合器,从而显着提高性能。附近的范围由限定的EdgeDirection参数,该参数取值为IN,OUT或ALL。IN将收集顶点的OUT所有进入边(邻居),ALL将收集所有外出边(邻居),同时收集所有边(邻居)。
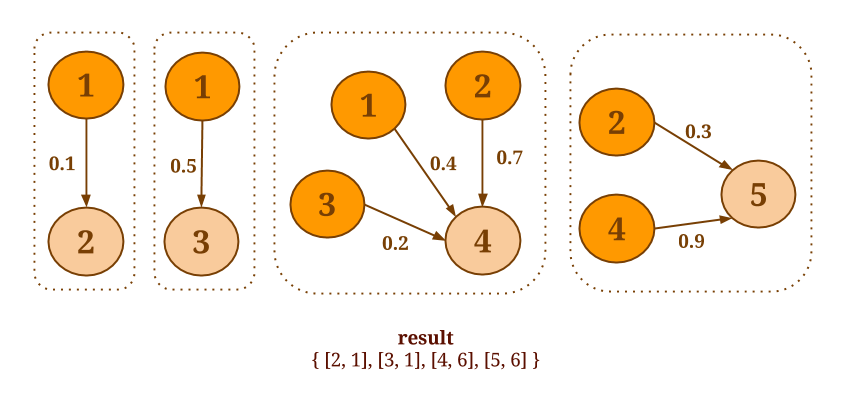
例如,假设您要在下图中为每个顶点选择所有外边的最小权重:
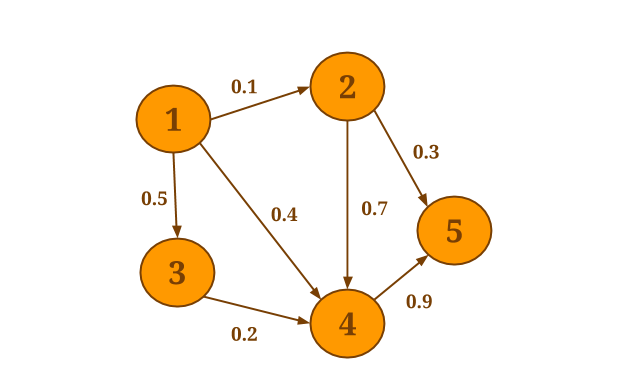
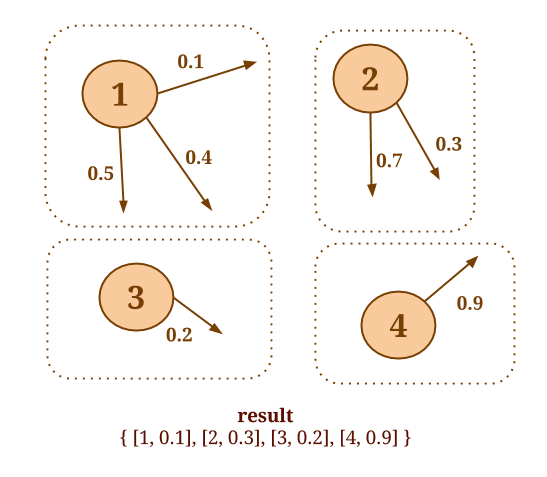
以下代码将收集每个顶点的外边缘,并SelectMinWeight()在每个结果邻域上应用用户定义的函数:
Graph<Long, Long, Double> graph = ...
DataSet<Tuple2<Long, Double>> minWeights = graph.reduceOnEdges(new SelectMinWeight(), EdgeDirection.OUT);
// user-defined function to select the minimum weight
static final class SelectMinWeight implements ReduceEdgesFunction<Double> {
@Override
public Double reduceEdges(Double firstEdgeValue, Double secondEdgeValue) {
return Math.min(firstEdgeValue, secondEdgeValue);
}
}
val graph: Graph[Long, Long, Double] = ...
val minWeights = graph.reduceOnEdges(new SelectMinWeight, EdgeDirection.OUT)
// user-defined function to select the minimum weight final class SelectMinWeight extends ReduceEdgesFunction[Double] {
override def reduceEdges(firstEdgeValue: Double, secondEdgeValue: Double): Double = {
Math.min(firstEdgeValue, secondEdgeValue)
}
}
类似地,假设您想为每个顶点计算所有进入邻居的值的总和。以下代码将收集每个顶点的进入邻居,并SumValues()在每个邻域上应用用户定义的函数:
Graph<Long, Long, Double> graph = ...
DataSet<Tuple2<Long, Long>> verticesWithSum = graph.reduceOnNeighbors(new SumValues(), EdgeDirection.IN);
// user-defined function to sum the neighbor values
static final class SumValues implements ReduceNeighborsFunction<Long> {
@Override
public Long reduceNeighbors(Long firstNeighbor, Long secondNeighbor) {
return firstNeighbor + secondNeighbor;
}
}
val graph: Graph[Long, Long, Double] = ...
val verticesWithSum = graph.reduceOnNeighbors(new SumValues, EdgeDirection.IN)
// user-defined function to sum the neighbor values final class SumValues extends ReduceNeighborsFunction[Long] {
override def reduceNeighbors(firstNeighbor: Long, secondNeighbor: Long): Long = {
firstNeighbor + secondNeighbor
}
}
当聚合作用是不关联的,并且交换或当期望返回每个顶点多于一个的值,可以使用更一般的 groupReduceOnEdges()和groupReduceOnNeighbors()的方法。这些方法每个顶点返回零个,一个或多个值,并提供对整个邻域的访问。
例如,以下代码将输出与权重为0.5或更大的边连接的所有顶点对:
Graph<Long, Long, Double> graph = ...
DataSet<Tuple2<Vertex<Long, Long>, Vertex<Long, Long>>> vertexPairs = graph.groupReduceOnNeighbors(new SelectLargeWeightNeighbors(), EdgeDirection.OUT);
// user-defined function to select the neighbors which have edges with weight > 0.5
static final class SelectLargeWeightNeighbors implements NeighborsFunctionWithVertexValue<Long, Long, Double,
Tuple2<Vertex<Long, Long>, Vertex<Long, Long>>> {
@Override
public void iterateNeighbors(Vertex<Long, Long> vertex,
Iterable<Tuple2<Edge<Long, Double>, Vertex<Long, Long>>> neighbors,
Collector<Tuple2<Vertex<Long, Long>, Vertex<Long, Long>>> out) {
for (Tuple2<Edge<Long, Double>, Vertex<Long, Long>> neighbor : neighbors) {
if (neighbor.f0.f2 > 0.5) {
out.collect(new Tuple2<Vertex<Long, Long>, Vertex<Long, Long>>(vertex, neighbor.f1));
}
}
}
}
val graph: Graph[Long, Long, Double] = ...
val vertexPairs = graph.groupReduceOnNeighbors(new SelectLargeWeightNeighbors, EdgeDirection.OUT)
// user-defined function to select the neighbors which have edges with weight > 0.5 final class SelectLargeWeightNeighbors extends NeighborsFunctionWithVertexValue[Long, Long, Double,
(Vertex[Long, Long], Vertex[Long, Long])] {
override def iterateNeighbors(vertex: Vertex[Long, Long],
neighbors: Iterable[(Edge[Long, Double], Vertex[Long, Long])],
out: Collector[(Vertex[Long, Long], Vertex[Long, Long])]) = {
for (neighbor <- neighbors) {
if (neighbor._1.getValue() > 0.5) {
out.collect(vertex, neighbor._2)
}
}
}
}
当聚合计算不需要访问顶点值(对其执行聚合)时,建议使用更高效的EdgesFunction和NeighborsFunction用户定义的函数。当需要访问顶点值时,应该使用EdgesFunctionWithVertexValue而NeighborsFunctionWithVertexValue不是。
图验证
Gelly提供了一个简单的实用程序,用于对输入图执行验证检查。根据应用程序上下文,图表可能根据某些标准有效,也可能无效。例如,用户可能需要验证其图形是否包含重复边或其结构是否为二分。为了验证图形,可以定义自定义GraphValidator并实现其validate()方法。InvalidVertexIdsValidator是Gelly的预定义验证器。它检查边集是否包含有效的顶点ID,即所有边ID都存在于顶点ID集中。
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// create a list of vertices with IDs = {1, 2, 3, 4, 5}
List<Vertex<Long, Long>> vertices = ...
// create a list of edges with IDs = {(1, 2) (1, 3), (2, 4), (5, 6)}
List<Edge<Long, Long>> edges = ...
Graph<Long, Long, Long> graph = Graph.fromCollection(vertices, edges, env);
// will return false: 6 is an invalid ID
graph.validate(new InvalidVertexIdsValidator<Long, Long, Long>());
val env = ExecutionEnvironment.getExecutionEnvironment
// create a list of vertices with IDs = {1, 2, 3, 4, 5} val vertices: List[Vertex[Long, Long]] = ...
// create a list of edges with IDs = {(1, 2) (1, 3), (2, 4), (5, 6)} val edges: List[Edge[Long, Long]] = ...
val graph = Graph.fromCollection(vertices, edges, env)
// will return false: 6 is an invalid ID graph.validate(new InvalidVertexIdsValidator[Long, Long, Long])
